








Advances in how "synchronized" is executed within Java Virtual Machines
By Gil Tene
Scaling in modern server applications clearly relies on multithreaded execution. With the abundance of multi-core and multi-threaded processors available from all vendors, highly threaded programs are required in order to leverage the concurrent execution capabilities of the underlying hardware. However, as more physical concurrency becomes available, Amdahl's law is becoming more and more relevant even for low end servers. To match this trend, and help stave off the effects of Amdahl's law, new technology for executing java synchronized blocks and methods concurrently rather than serially has emerged, and is already shipping in some commercial JVMs.
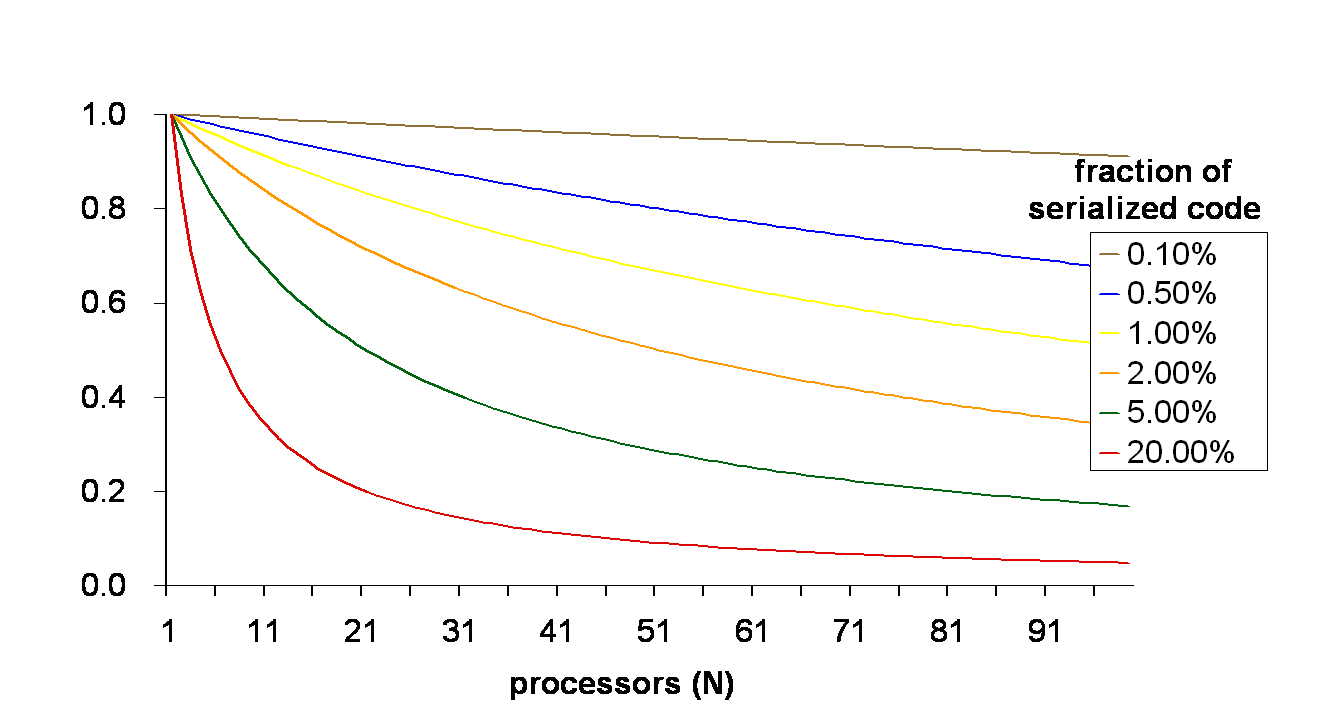
The scaling problem is not a new one. Amdahl's law has been with us for almost four decades, and simply stated, it describes the expected improvement to a system's overall performance when only a part of the system is improved. When applied to parallelization, Amdahl's law shows that if F is the fraction of execution that is sequential (and does not benefit from parallelization), and (1-F) is the fraction of execution that can be parallelized, then the maximum speedup that can be achieved by N concurrent execution units is 1/(F + (1-F)/N). In the limit, as number of execution units N tends towards infinity, the maximum speedup tends to 1/F.
For example, in a program where 10% of execution is performed serially, F is 0.1, and the highest possible speedup the program can gain from multiple execution units is 10x regardless of the number of execution units. With 10 execution units, the program would only gain a 5.26x speedup, and with 16 execution units the program would only gain 6.4x speedup.
These diminishing returns are affecting Java server program scaling today, as commodity servers are now available with 16 concurrent execution units and even more, and servers with 100s of execution units are readily available. The trend towards scaling by means of hardware parallelism is clear. As the number of execution units grows, so does our sensitivity to the limitations of serial execution.
Why does serialization happen?
Serial execution in multithreaded programs is most generally caused by the use of synchronization. In all such programs, there are certain sets of operations that affect data, and must appear to execute atomically when observed by other threads in order to maintain program correctness. The classic case of multiple concurrent deposits or withdrawals from a common balance is often used to demonstrate the need for synchronization. Unsynchronized data access can easily cause erroneous results.
In Java, these atomic sets of operations are typically protected by Java synchronized blocks or Java synchronized methods. A synchronized object instance carries a Java monitor, which is used to synchronize access to the code section. Java Virtual Machines usually execute Java synchronized blocks using an underlying lock acquisition and release as a means of synchronization, with the lock typically associated with the Java Monitor.
Lock contentions vs. Data Contention
It is important to differentiate between lock contention and data contention. We define Lock contention as an actual attempt to acquire a lock when another thread is holding it. We define data contention as an actual attempt by one thread to access data that another thread expects to manipulate atomically.
In practice, as access to large or complex data structures is synchronized, lock contention is much more common that actual data contention. This difference is often measured in orders of magnitude. This demonstrates that lock acquisition and release as a means of synchronization is and inherently pessimistic means of assuring data access atomicity, and serializes execution to a much higher degree that is necessary.
However, the problem of assuring atomic data access without serializing on locks is a "hard" one. Detecting and resolving concurrent data access is not easily done or expressed in multithreaded programs.
This is not a new problem. Databases and transaction monitors have been addressing the competing needs of concurrency, atomicity, and scale for decades. Optimistic concurrent execution of transactions in most database platforms is a clear example. In such implementations, the semantics of transaction execution, failure detection, and rollback are exposed to the controlling program, so that higher concurrency can be achieved.
What does "synchronized" really mean?
The only actual expectation we can have of synchronized blocks is that they make the operations within them appear to execute atomically. We tend to think of synchronized block execution as "grab a lock on the synchronized object; execute the block release the lock", and that is certainly a correct way of executing a synchronized block, but is it the only way?
The Java Virtual Machine specification and the Java Memory Model (JSR133) define the semantics of "synchronized". A simple representation can be summarized as:
"execute block atomically in relation to other blocks synchronizing on the same object"
This is actually a fairly loose synchronization level, and can be easily covered by a more conservative requirement stated as:
"execute block atomically in relation to all other threads"
This looks a lot like a transaction. While serializing execution of a block at all times using a lock is a correct means of executing it, executing "synchronized" as a transactional operation is just as valid. A JVM that executes synchronized blocks as transactional operations is able to execute such blocks concurrently in many threads, rather than serially, as long as no data contention occurs.
In order to support such transactional execution, the JVM must detect data contention within the transactional block. When data contention does occur, the JVM must roll the entire execution state of the thread that experienced data contention back to the beginning of the synchronized block. Thread execution can then be resumed, as the block had not yet been entered.
It's real, and it's here
Such data detection and roll back capabilities in a JVM could be implemented in various ways. Performing data contention detection, state saving, and rollback can be potentially be done in a JVM using pure software techniques, much in the same way databases and related application resolve concurrency and scale problems. However, such JVM implementations likely come with significant cost, slowdowns, risk and complexity. Hardware support for data contention detection can be used to resolve most these issues, and various level of such support in future processors has been discussed in academic circles for over a decade.
While such capability may seem futuristic, we now have commercially shipping platforms that provide it. Optimistic concurrency assisted, network attached processing capacity is available for JVMs running on Solaris, Linux, HPUX, and AIX.
The effect of transactional, adaptive execution of synchronized blocks on scalability can be profound, and may change your point of view and coding practices with regards to synchronization and scale.
For more details, come see our JAOO talk about on Speculative Locking: breaking the scale barrier on Wednesday, Sep. 28th, or visit www.azulsystems.com
